When working with curves in Grasshopper, it’s sometimes useful to remove duplicate curves. The more curves are processed in an algorithm, the longer does the computation take for each step. Also, duplicate curves might lead to mistakes in quantifycations and other calculations.
Kangaroo2 has a utility component removeDuplicateLines removeDuplicateLines (dupLn)
removeDuplicateLines (dupLn)Inputs lines (L) list of lines to clean tolerance (t) lines with start/endpoints closer than this distance will be combined Outputs unique lines (Q) list of unique lines  Remove Duplicate Lines (Karamba3D) (RDLines)
Remove Duplicate Lines (Karamba3D) (RDLines)Inputs Line (L) Input Lines Limit distance (LDist) Limit Distance for coincident points Outputs OutLine (L) Output Lines Info (Info) Information regarding the removal of duplicate lines Indexes (I) Indexes of removed lines
Remove duplicate curves (simple comparison)
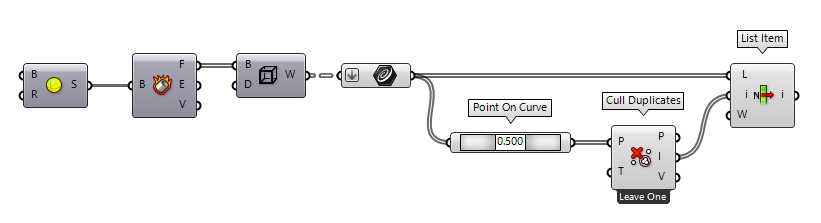
Before we can remove anything, we have to identify the properties that duplicate curves share and which can be used to identify the duplicates. Often, it’s sufficient to check for identical midpoints. For example in those cases, when the duplicate curves were created by the edges of two adjacent surfaces.
The first step is to bundle all curves in a list and to flatten them if
needed. Then we use Point On Curve Point On Curve (CurvePoint)
Point On Curve (CurvePoint) Cull Duplicates (CullPt)
Cull Duplicates (CullPt)Inputs Points (P) Points to operate on Tolerance (T) Proximity tolerance distance Outputs Points (P) Culled points Indices (I) Index map of culled points Valence (V) Number of input points represented by this output point  List Item (Item)
List Item (Item)Inputs List (L) Base list Index (i) Item index Wrap (W) Wrap index to list bounds Outputs Item (i) Item at {i'}
Remove duplicate curves (advanced comparison)
There can be cases in which deviant curves meet at their midpoints, for example in an X. With the previous method, those curves would be falsely identified as duplicates. If we suspect that this case might occur, we have to think of a more advanced method for comparison; one that takes various criteria into account. Then, if all criteria match, we can assume that the curves are congruent.
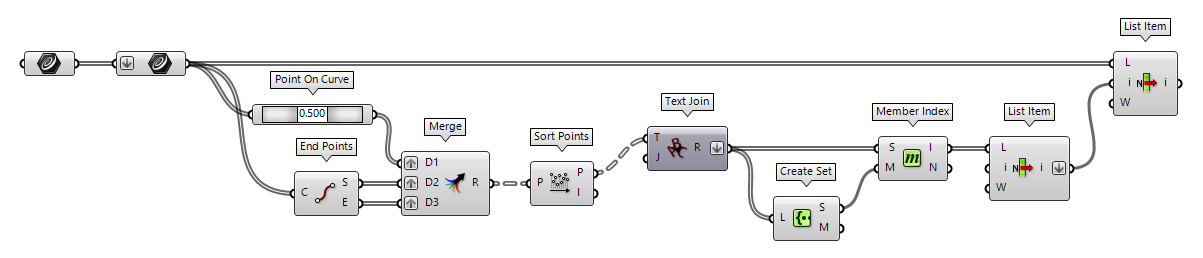
To proceed with this idea, we will concatenate the curves' attributes into a string, which we use a simplified hash value. Then we compare these hashes to identify duplicate curves. In this example, we will use the endpoints as additional attributes.
After bundling all curves, we will use Point On Curve
Point On Curve (CurvePoint) End Points (End)
End Points (End)Inputs Curve (C) Curve to evaluate Outputs Start (S) Curve start point End (E) Curve end point  Merge (Merge)
Merge (Merge)Inputs Data 1 (D1) Data stream 1 Data 2 (D2) Data stream 2 Outputs Result (R) Result of merge  Sort Points (Sort Pt)
Sort Points (Sort Pt)Inputs Points (P) Points to sort Outputs Points (P) Sorted points Indices (I) Point index map  Text Join (Join)
Text Join (Join)Inputs Text (T) Text fragments to join. Join (J) Fragment separator. Outputs Result (R) Resulting text
Next, we flatten the hashes and use Create Set Create Set (CSet)
Create Set (CSet)Inputs List (L) List of data. Outputs Set (S) A set of all the distincts values in L Map (M) An index map from original indices to set indices  Member Index (MIndex)
Member Index (MIndex)Inputs Set (S) Set to operate on. Member (M) Member to search for. Outputs Index (I) Indices of member. Count (N) Number of occurences of the member.
List Item (Item)Inputs List (L) Base list Index (i) Item index Wrap (W) Wrap index to list bounds Outputs Item (i) Item at {i'}
List Item (Item)Inputs List (L) Base list Index (i) Item index Wrap (W) Wrap index to list bounds Outputs Item (i) Item at {i'}
This advanced comparison can be extended to check for more attributes that make a curve unique, like tangents at the endpoints. Also, this principle can be applied to other geometries; we just have to think about the properties that congruent objects share. To regard tolerances, we could round the properties and adjust their decimal places before we translate them into a string.